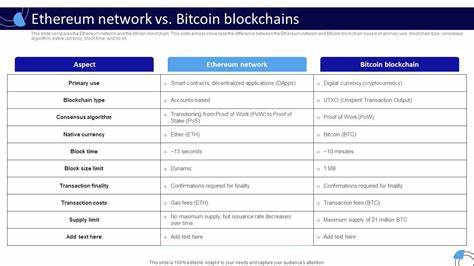
查询优化器在现代数据库系统中扮演着至关重要的角色。作为决定SQL查询执行计划的核心模块,它负责在众多可能的执行策略中挑选出最优方案,从而最大化系统性能和资源利用效率。尽管查询优化器历经数十年发展,但其技术细节仍被业界视为黑盒,许多用户和开发人员对其实际效能存在迷思。问题的核心在于:查询优化器真的已经足够优秀,能够满足现代复杂应用的需求吗? 从技术发展的角度来看,查询优化器最经典的设计源于1970年代的Selinger算法,它提出了基于成本模型的代价估算与执行计划枚举,开创了代价基查询优化的先河。这种设计理念的优势在于理论上能够通过穷尽计划空间,结合准确的成本和基数估计,找到全局最优的执行策略。然而,现实情况却远比理论复杂,更大规模的数据、多表连接以及数据分布的非均匀性,给优化器带来了前所未有的挑战。
近年来,学术界和工业界对查询优化器的性能进行了系统化的评估和分析。特别是由维克托·赖斯和其团队在2015年发表的研究,引入了被称为Join Order Benchmark(JOB)的基准测试。这项研究针对优化器的关键组成部分 - - 计划枚举、成本模型和基数估计的表现进行了细致拆分,揭示了优化器表现不佳的根本原因。结果表明,尽管计划枚举和成本模型的缺陷在一定程度上影响查询性能,但统计数据的准确性,尤其是中间结果基数的估计误差,才是性能瓶颈的关键所在。 基数估计的困难源自数据库统计信息的稀疏和不完备。许多现有优化器依赖简单的独立性假设和单变量列统计,难以捕捉复杂数据分布的联动关系。
这就导致对多表、多条件过滤结果行数估计远低于或远高于实际,最终产生了次优甚至极差的执行计划。此外,这些估计误差常常以数量级的差距出现,极大地影响了后续的成本模型校准和计划选择。 这也解释了业界为何频繁出现因查询计划不佳而产生性能瓶颈或执行失败的情况。大型企业中的数据库管理员和开发团队时常需要通过索引调整、查询重写或者Hint强制优化器使用特定执行路径,来规避优化器的不足。这种人为干预不仅增加了运营成本,还限制了系统的自适应能力和扩展性。 为应对上述挑战,近年来新兴的机器学习与人工智能技术开始被引入查询优化器的研发中。
学术界和业界尝试利用深度学习模型结合历史执行数据预测查询基数,从而提升估计准确度。同时,基于反馈机制的自适应执行技术也逐渐成熟,允许系统在查询执行过程中实时调整执行策略,缓解静态优化带来的限制。这些技术的发展为未来的查询优化器带来了更高的鲁棒性和智能化。 除了技术创新,研究人员还高度重视基准测试设计的重要性。Join Order Benchmark作为业界首个系统性评估查询优化器核心能力的开源工具,极大地推动了该领域的复兴。通过模拟真实业务场景中的复杂多表连接和多样数据分布,JOB标准测试为优化器的设计和调优提供了更贴近实际的参考。
社区共同努力,使得查询优化研究重新焕发活力,成为数据库性能提升的重要突破口。 当然,查询优化领域仍有不少难题尚需攻克。例如,面对云计算和大数据场景中的弹性资源分配、多租户环境、分布式数据库的查询优化器性能保障,以及异构数据存储和混合工作负载下的优化策略设计,都是未来亟须突破的关键方向。如何在保持优化效率的同时保证计划的适应性和鲁棒性,是开拓新一代查询优化技术的核心议题。 综上所述,尽管基础的成本模型和枚举策略逐步趋于成熟,查询优化器的"真相"表明其最大挑战仍然扎根于卡迪纳尔估计的精度不足。优化器技术正经历从传统规则驱动向数据驱动智能化的转变,从而力图实现更强的查询性能提升和自动化能力。
未来查询优化的道路充满机遇,也充满挑战,持续关注和深入研究这一领域,将助力数据库系统在不断增长的应用需求面前保持高效和稳定。 。