随着人工智能和机器学习技术的飞速发展,数据处理和特征工程成为构建高效智能模型的关键环节,而如何保证线上和线下数据的一致性、实现复杂数据转换与实时请求的低延迟响应,成为许多企业面临的挑战。Chronon应运而生,作为一个专为AI/ML应用打造的数据服务平台,它不仅抽象了数据计算和服务的复杂性,还集成了批处理与流式计算,实现了可扩展、准确且高效的特征计算。Chronon让数据科学家和工程师能够专注于特征的定义和业务逻辑,而无须操心底层繁琐的数据编排、同步和一致性问题,显著提升研发效率和模型上线质量。Chronon的设计理念基于对在线特征服务和离线训练数据一致性的强烈需求。在传统的数据流水线中,批量训练和实时推断往往依赖两套独立的数据处理系统,导致数据转换逻辑分散且易出错,影响模型的性能和稳定性。Chronon则将这两者统一起来,通过统一的API定义特征,使得无论是用于训练的历史数据回填,还是用于模型在线推断的实时特征,都能保证时间点上的严格一致,避免了标签泄漏等问题,从根源上解决了许多数据偏差和不协调的难题。
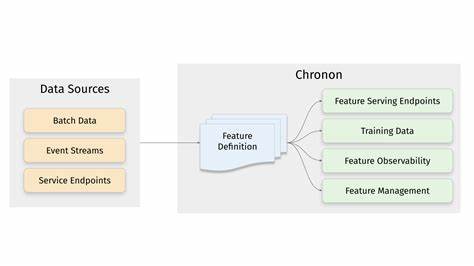
平台支持从组织内部的各种数据源采集信息,涵盖批表、事件流以及服务调用等多维数据形式,不受数据来源限制,为复杂、多样化的AI项目提供全面的数据保障。用户只需在平台上定义原始数据的转换和聚合逻辑,Chronon即可自动完成大规模数据的批量计算和流式更新,支持复杂的时间窗口聚合、多种统计操作,实现特征的动态变化追踪和实时展现。Chronon对在线服务的支持可谓一大亮点。平台提供了灵活的API接口,允许用户低延迟地获取最新特征值,适应高度分布式和fanout大的请求场景,确保模型推断时能够快速获取准确的输入信息。无论是秒级响应的推荐系统,还是实时风控模型,都能从中获益。此外,Chronon内置了全面的数据监控和观测能力,帮助用户实时跟踪数据的新鲜度、转换的正确性以及线上与线下数据的一致性指标,便于快速定位异常,确保数据质量。
这样一套完善的监控机制进一步保障了模型的稳定和业务的持续健康。Chronon的使用流程清晰且友好。首先,用户定义原始数据的转换规则,通常采用GroupBy等聚合方式对事件数据进行维度切分和统计计算。接着,利用Join操作将多个特征集合合并,构建成面向训练的宽表,实现模型所需的全量特征视图。完成定义后,平台支持高效地进行历史数据回填,生成全量训练集。同时,为线上推理场景上传最新数据,实现模型实时特征的检索。
值得一提的是,Chronon不仅支持批处理的数据路径,也兼容流式计算,使得数据处理更加灵活,能够应对延时要求严格的环境。平台内部利用Spark等大数据引擎完成计算任务,保证了系统的可伸缩性和高性能。关于实际应用价值,Chronon帮助企业大幅缩短了模型上线周期。通过确保一致性和简化数据流水线搭建,减少了上下游系统的运维压力。它不仅适合电商、金融风控、互联网广告等领域,还适用于任何对实时智能服务有高需求的行业。由于支持多来源数据融合,模型可以挖掘更丰富的信息,提升预测效果和决策精准度。
从开发者角度看,Chronon提供了完善的文档和示范用例,使用户能够快速上手。结合Docker Compose等工具,实现快速搭建和本地测试。其设计良好的接口和工具链方便团队协作,优化了功能迭代的效率。此外,平台采用开源许可证发布,鼓励社区贡献,推动技术持续进步。Chronon区别于传统两套数据处理方案的革新在于它将训练数据的回填和在线推理的特征查询系统集成于一个统一的计算平台中,保障时间点的准确对齐和数据一致。相比"先记录日志后等待训练"的方案,其特征聚合能力更强,支持复杂时间窗口计算,也克服了单纯复制离线计算逻辑线上实现的难点。
相较于纯模仿数据仓库做法,Chronon显著简化工程工作量,并具备更好的扩展性和实时性。综上所述,Chronon作为集特征定义、计算、服务和监控为一体的数据平台,展示了未来智能系统数据底座的一个重要方向。它的出现既解决了AI/ML项目中常见的特征一致性和复杂数据处理难题,也提升了企业应对实时业务需求的能力。随着人工智能技术日益普及,高效、准确的数据平台变得愈发关键。选择并掌握Chronon,等于为数据驱动的智能未来奠定坚实基础。 。